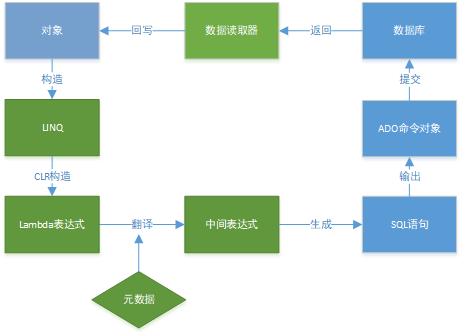
对于ORM一定是以对象为起点,使用对象构造出LINQ表达式,这样我们在对象的世界中可以描述我们希望对数据库所进行的操作,LINQ的最终实现其实也是Lambda表达式(毕竟LINQ在代码上会直观很多),功能较强的ORM中都会记录对象类型到数据库对象的元数据,使用这些元数据可以将复杂的Lambda表达式翻译成一个通用的中间表达式,这个表达式其实是抽象于各个不同数据库的具体实现,最后中间表达式再按指定数据库的具体实现生成最终的SQL语句,交由ADO.NET对象执行到数据库,如果数据存在返回则会回写到CLR对象中。
聚集索引: 数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。 聚集索引的好处,索引的叶子节点就是对应的数据节点,可以直接获取到对应的全部列的数据,而非聚集索引在索引没有覆盖到对应的列的时候需要进行二次查询。因此在查询方面,聚集索引的速度往往会更占优势。 注意:SQL Sever默认主键为聚集索引,也可以指定为非聚集索引,而MySQL里主键就是聚集索引。
非聚集索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。 非聚集索引的二次查询问题:非聚集索引叶节点仍然是索引节点,只是有一个指针指向对应的数据块,此如果使用非聚集索引查询,而查询列中包含了其他该索引没有覆盖的列,那么他还要进行第二次的查询,查询节点上对应的数据行的数据。 要注意的是非聚集索引其实叶子节点除了会存储索引覆盖列的数据,也会存放聚集索引所覆盖的列数据。
如何解决非聚集索引的二次查询问题? 建立两列以上的索引(复合索引),即可查询复合索引里的列的数据而不需要进行回表二次查询。建立两列以上的索引,即可查询复合索引里的列的数据而不需要进行回表二次查询。
- 使用聚集索引的查询效率要比非聚集索引的效率要高,但是如果需要频繁去改变聚集索引的值,写入性能并不高,因为需要移动对应数据的物理位置。
- 非聚集索引在查询的时候可以的话就避免二次查询,这样性能会大幅提升。
- 不是所有的表都适合建立索引,只有数据量大表才适合建立索引,且建立在选择性高的列上面性能会更好。
为列创建索引实际上就是为列进行排序,以方便查询。建立一个列的索引,就相当于建立一个列的排序。
主键是唯一的,所以创建了一个主键的同时,这个字段也就创建了一个唯一的索引,唯一索引实际上就是要求指定的列中所有的数据必须不同。
主键与唯一索引的区别:
- 一个表的主键只能有一个,而唯一索引可以建多个。
- 主键可以作为其它表的外键。
- 主键不可为null,唯一索引可以为null。
聚集索引:将表内的数据按照一定的规则进行排列的目录。正因为如此,一个表中的聚集索引只有一个。对此我们要注意“主键就是聚集索引”这是极端错误的,是对聚集索引的一种浪费。(虽然SQL Server默认主键就是聚集索引)使用聚集索引的最大好处就是按照查询要求,迅速缩小查询范围,避免进行全表扫描。
索引的作用
- 帮助检索数据;
- 提高联接效率;
- 节省ORDER BY、GROUP BY的时间;
- 保证数据唯一性(仅限于唯一索引)。
索引的设计
在确定要建立一个索引时,首先我们要确定它是聚集还是非聚集、单列还是多列、唯一还是非唯一、列是升序还是降序、它的存储是如何的,比如:分区、填充因子等。
聚集索引
- 首先指出一个误区,主键并不一定是聚集索引,只是在SQL SERVER中,未明确指出的情况下,默认将主键定义为聚集,而ORACLE中则默认是非聚集,因为SQL SERVER中的ROWID未开放使用。
- 聚集索引适合用于需要进行范围查找的列,因为聚集索引的叶子节点存放的是有序的数据行,查询引擎可根据WHERE中给出的范围,直接定位到两端的叶子节点,将这部分节点页的数据根据链表顺序取出即可;
- 聚集索引尽量建立在值不会发生变更的列上,否则会带来非聚集索引的维护;
- 尽量在建立非聚集索引之前建立聚集索引,否则会导致表上所有非聚集索引的重建;
- 聚集索引应该避免建立在数值单调的列上,否则可能会造成IO的竞争,以及B树的不平衡,从而导致数据库系统频繁的维护B树的平衡性。聚集索引的列值最好能够在表中均匀分布。
唯一索引
- 再指出一个误区,聚集索引并不一定是唯一索引,由于SQL SERVER将主键默认定义为聚集索引,事实上,索引是否唯一与是否聚集是不相关的,聚集索引可以是唯一索引,也可以是非唯一索引;
- 将索引设置为唯一,对于等值查找是很有利的,当查到第一条符合条件的纪录时即可停止查找,返回数据,而非唯一索引则要继续查找,同样,由于需要保证唯一性,每一行数据的插入都会去检查重复性。
对多个字段同时建立的索引(有顺序,ABC,ACB是完全不同的两种联合索引)。
以联合索引(a,b,c)为例,建立这样的索引相当于建立了索引a、ab、abc三个索引。一个索引顶三个索引当然是好事,毕竟每多一个索引,都会增加写操作的开销和磁盘空间的开销,联合索引的顺序非常重要,这个要切记。
使用一个具有两列的索引不同于使用两个单独的索引。创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
重点:
多个单列索引在多条件查询时优化器会选择最优索引策略,可能只用一个索引,也可能将多个索引全用上! 但多个单列索引底层会建立多个B+索引树,比较占用空间,也会浪费一定搜索效率,故如果只有多条件联合查询时最好建联合索引!
最左前缀原则:
顾名思义是最左优先,以最左边的为起点任何连续的索引都能匹配上,
注:如果第一个字段是范围查询需要单独建一个索引
注:在创建联合索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。这样的话扩展性较好,比如 userid 经常需要作为查询条件,而 mobile 不常常用,则需要把 userid 放在联合索引的第一位置,即最左边
同时存在联合索引和单列索引(字段有重复的),这个时候查询mysql会怎么用索引呢?这个涉及到mysql本身的查询优化器策略了,当一个表有多条索引可走时, Mysql 根据查询语句的成本来选择走哪条索引;
有人说where查询是按照从左到右的顺序,所以筛选力度大的条件尽量放前面。网上百度过,很多都是这种说法,但是据我研究,mysql执行优化器会对其进行优化,当不考虑索引时,where条件顺序对效率没有影响,真正有影响的是是否用到了索引!
联合索引本质
当创建(a,b,c)联合索引时,可以理解为创建了(a)单列索引,(a,b)联合索引以及(a,b,c)联合索引,但是实际上没有创建,只是为了好理解。
想要索引生效的话,只能使用 a和a,b和a,b,c三种组合;当然,经过测试,a,c组合也可以,但实际上只用到了a的索引,c并没有用到!
其他知识点
- 需要加索引的字段,要在where条件中
- 数据量少的字段不需要加索引;因为建索引有一定开销,如果数据量小则没必要建索引(速度反而慢)
- 避免在where子句中使用or来连接条件,因为如果俩个字段中有一个没有索引的话,引擎会放弃索引而产生全表扫描
- 联合索引比对每个列分别建索引更有优势,因为索引建立得越多就越占磁盘空间,在更新数据的时候速度会更慢。另外建立多列索引时,顺序也是需要注意的,应该将严格的索引放在前面,这样筛选的粒度会更大,效率更高。
在Customer表(Id,UserName)中,删除同名的数据,仅保留Id最小的一条数据。
--思路分析如下:
--1.找出重复的Name
select Username from Customer GROUP BY Username HAVING COUNT(*)>1;
--2.找出重复Name所在行的Id
select Id from Customer where Username in (
select Username from Customer GROUP BY Username HAVING COUNT(*)>1
);
--3.找到重复Name行最小的Id
select Min(Id) from Customer GROUP BY Username HAVING COUNT(*)>1;
--4.删除其他数据,保留最小的Id所在行数据
--所以最终结果如下:
delete from Customer where
Id in (
select Id from Customer where Username in (
select Username from Customer GROUP BY Username HAVING COUNT(*)>1
)
)
and Id not in(
select Min(Id) from Customer GROUP BY Username HAVING COUNT(*)>1
);
下面我们来具体分析一下查询处理的每一个阶段
FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
ON: 对虚表VT1进行ON筛选,只有那些符合join-condition的行才会被记录在虚表VT2中。
JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止
WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合where-condition的记录才会被插入到虚拟表VT4中。
GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
HAVING: 对虚拟表VT6应用having过滤,只有符合having-condition的记录才会被 插入到虚拟表VT7中。
SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
ORDER BY: 将虚拟表VT9中的记录按照order_by_list进行排序操作,产生虚拟表VT10.
LIMIT/Top:取出指定行的记录,产生虚拟表VT11, 并将结果返回。
书写顺序:select ... from... where.... group by... having... order by.. limit [Top,]
(rows)
执行顺序:from... where...group by... having.... select ... order by... limit[Top]