
![]()

Stable: v1.7.3 / Roadmap | F.A.Q.
High-performance inference of OpenAI's Whisper automatic speech recognition (ASR) model:
- Plain C/C++ implementation without dependencies
- Apple Silicon first-class citizen - optimized via ARM NEON, Accelerate framework, Metal and Core ML
- AVX intrinsics support for x86 architectures
- VSX intrinsics support for POWER architectures
- Mixed F16 / F32 precision
- Integer quantization support
- Zero memory allocations at runtime
- Vulkan support
- Support for CPU-only inference
- Efficient GPU support for NVIDIA
- OpenVINO Support
- Ascend NPU Support
- C-style API
Supported platforms:
- Mac OS (Intel and Arm)
- iOS
- Android
- Java
- Linux / FreeBSD
- WebAssembly
- Windows (MSVC and MinGW]
- Raspberry Pi
- Docker
The entire high-level implementation of the model is contained in whisper.h and whisper.cpp.
The rest of the code is part of the ggml machine learning library.
Having such a lightweight implementation of the model allows to easily integrate it in different platforms and applications. As an example, here is a video of running the model on an iPhone 13 device - fully offline, on-device: whisper.objc
whisper-iphone-13-mini-2.mp4
You can also easily make your own offline voice assistant application: command
command-0.mp4
On Apple Silicon, the inference runs fully on the GPU via Metal:
metal-base-1.mp4
First clone the repository:
git clone https://github.com/ggerganov/whisper.cpp.gitNavigate into the directory:
cd whisper.cpp
Then, download one of the Whisper models converted in ggml format. For example:
sh ./models/download-ggml-model.sh base.enNow build the whisper-cli example and transcribe an audio file like this:
# build the project
cmake -B build
cmake --build build --config Release
# transcribe an audio file
./build/bin/whisper-cli -f samples/jfk.wavFor a quick demo, simply run make base.en.
The command downloads the base.en model converted to custom ggml format and runs the inference on all .wav samples in the folder samples.
For detailed usage instructions, run: ./build/bin/whisper-cli -h
Note that the whisper-cli example currently runs only with 16-bit WAV files, so make sure to convert your input before running the tool.
For example, you can use ffmpeg like this:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavIf you want some extra audio samples to play with, simply run:
make -j samples
This will download a few more audio files from Wikipedia and convert them to 16-bit WAV format via ffmpeg.
You can download and run the other models as follows:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| Model | Disk | Mem |
|---|---|---|
| tiny | 75 MiB | ~273 MB |
| base | 142 MiB | ~388 MB |
| small | 466 MiB | ~852 MB |
| medium | 1.5 GiB | ~2.1 GB |
| large | 2.9 GiB | ~3.9 GB |
whisper.cpp supports integer quantization of the Whisper ggml models.
Quantized models require less memory and disk space and depending on the hardware can be processed more efficiently.
Here are the steps for creating and using a quantized model:
# quantize a model with Q5_0 method
cmake -B build
cmake --build build --config Release
./build/bin/quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./build/bin/whisper-cli -m models/ggml-base.en-q5_0.bin ./samples/gb0.wavOn Apple Silicon devices, the Encoder inference can be executed on the Apple Neural Engine (ANE) via Core ML. This can result in significant
speed-up - more than x3 faster compared with CPU-only execution. Here are the instructions for generating a Core ML model and using it with whisper.cpp:
-
Install Python dependencies needed for the creation of the Core ML model:
pip install ane_transformers pip install openai-whisper pip install coremltools
- To ensure
coremltoolsoperates correctly, please confirm that Xcode is installed and executexcode-select --installto install the command-line tools. - Python 3.10 is recommended.
- MacOS Sonoma (version 14) or newer is recommended, as older versions of MacOS might experience issues with transcription hallucination.
- [OPTIONAL] It is recommended to utilize a Python version management system, such as Miniconda for this step:
- To create an environment, use:
conda create -n py310-whisper python=3.10 -y - To activate the environment, use:
conda activate py310-whisper
- To create an environment, use:
- To ensure
-
Generate a Core ML model. For example, to generate a
base.enmodel, use:./models/generate-coreml-model.sh base.en
This will generate the folder
models/ggml-base.en-encoder.mlmodelc -
Build
whisper.cppwith Core ML support:# using CMake cmake -B build -DWHISPER_COREML=1 cmake --build build -j --config Release -
Run the examples as usual. For example:
$ ./build/bin/whisper-cli -m models/ggml-base.en.bin -f samples/jfk.wav ... whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc' whisper_init_state: first run on a device may take a while ... whisper_init_state: Core ML model loaded system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 | ...The first run on a device is slow, since the ANE service compiles the Core ML model to some device-specific format. Next runs are faster.
For more information about the Core ML implementation please refer to PR #566.
On platforms that support OpenVINO, the Encoder inference can be executed on OpenVINO-supported devices including x86 CPUs and Intel GPUs (integrated & discrete).
This can result in significant speedup in encoder performance. Here are the instructions for generating the OpenVINO model and using it with whisper.cpp:
-
First, setup python virtual env. and install python dependencies. Python 3.10 is recommended.
Windows:
cd models python -m venv openvino_conv_env openvino_conv_env\Scripts\activate python -m pip install --upgrade pip pip install -r requirements-openvino.txt
Linux and macOS:
cd models python3 -m venv openvino_conv_env source openvino_conv_env/bin/activate python -m pip install --upgrade pip pip install -r requirements-openvino.txt
-
Generate an OpenVINO encoder model. For example, to generate a
base.enmodel, use:python convert-whisper-to-openvino.py --model base.enThis will produce ggml-base.en-encoder-openvino.xml/.bin IR model files. It's recommended to relocate these to the same folder as
ggmlmodels, as that is the default location that the OpenVINO extension will search at runtime. -
Build
whisper.cppwith OpenVINO support:Download OpenVINO package from release page. The recommended version to use is 2023.0.0.
After downloading & extracting package onto your development system, set up required environment by sourcing setupvars script. For example:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (cmd):
C:\Path\To\w_openvino_toolkit_windows_2023.0.0.10926.b4452d56304_x86_64\setupvars.bat
And then build the project using cmake:
cmake -B build -DWHISPER_OPENVINO=1 cmake --build build -j --config Release
-
Run the examples as usual. For example:
$ ./build/bin/whisper-cli -m models/ggml-base.en.bin -f samples/jfk.wav ... whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml' whisper_ctx_init_openvino_encoder: first run on a device may take a while ... whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache whisper_ctx_init_openvino_encoder: OpenVINO model loaded system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 | ...The first time run on an OpenVINO device is slow, since the OpenVINO framework will compile the IR (Intermediate Representation) model to a device-specific 'blob'. This device-specific blob will get cached for the next run.
For more information about the Core ML implementation please refer to PR #1037.
With NVIDIA cards the processing of the models is done efficiently on the GPU via cuBLAS and custom CUDA kernels.
First, make sure you have installed cuda: https://developer.nvidia.com/cuda-downloads
Now build whisper.cpp with CUDA support:
cmake -B build -DGGML_CUDA=1
cmake --build build -j --config Release
Cross-vendor solution which allows you to accelerate workload on your GPU. First, make sure your graphics card driver provides support for Vulkan API.
Now build whisper.cpp with Vulkan support:
cmake -B build -DGGML_VULKAN=1
cmake --build build -j --config Release
Encoder processing can be accelerated on the CPU via OpenBLAS.
First, make sure you have installed openblas: https://www.openblas.net/
Now build whisper.cpp with OpenBLAS support:
cmake -B build -DGGML_BLAS=1
cmake --build build -j --config Release
Ascend NPU provides inference acceleration via CANN and AI cores.
First, check if your Ascend NPU device is supported:
Verified devices
| Ascend NPU | Status |
|---|---|
| Atlas 300T A2 | Support |
Then, make sure you have installed CANN toolkit . The lasted version of CANN is recommanded.
Now build whisper.cpp with CANN support:
cmake -B build -DGGML_CANN=1
cmake --build build -j --config Release
Run the inference examples as usual, for example:
./build/bin/whisper-cli -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
Notes:
- If you have trouble with Ascend NPU device, please create a issue with [CANN] prefix/tag.
- If you run successfully with your Ascend NPU device, please help update the table
Verified devices.
You can install pre-built binaries for whisper.cpp or build it from source using Conan. Use the following command:
conan install --requires="whisper-cpp/[*]" --build=missing
For detailed instructions on how to use Conan, please refer to the Conan documentation.
- Inference only
This is a naive example of performing real-time inference on audio from your microphone. The stream tool samples the audio every half a second and runs the transcription continuously. More info is available in issue #10.
cmake -B build
cmake --build build --config Release
./build/bin/stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000rt_esl_csgo_2.mp4
Adding the --print-colors argument will print the transcribed text using an experimental color coding strategy
to highlight words with high or low confidence:
./build/bin/whisper-cli -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors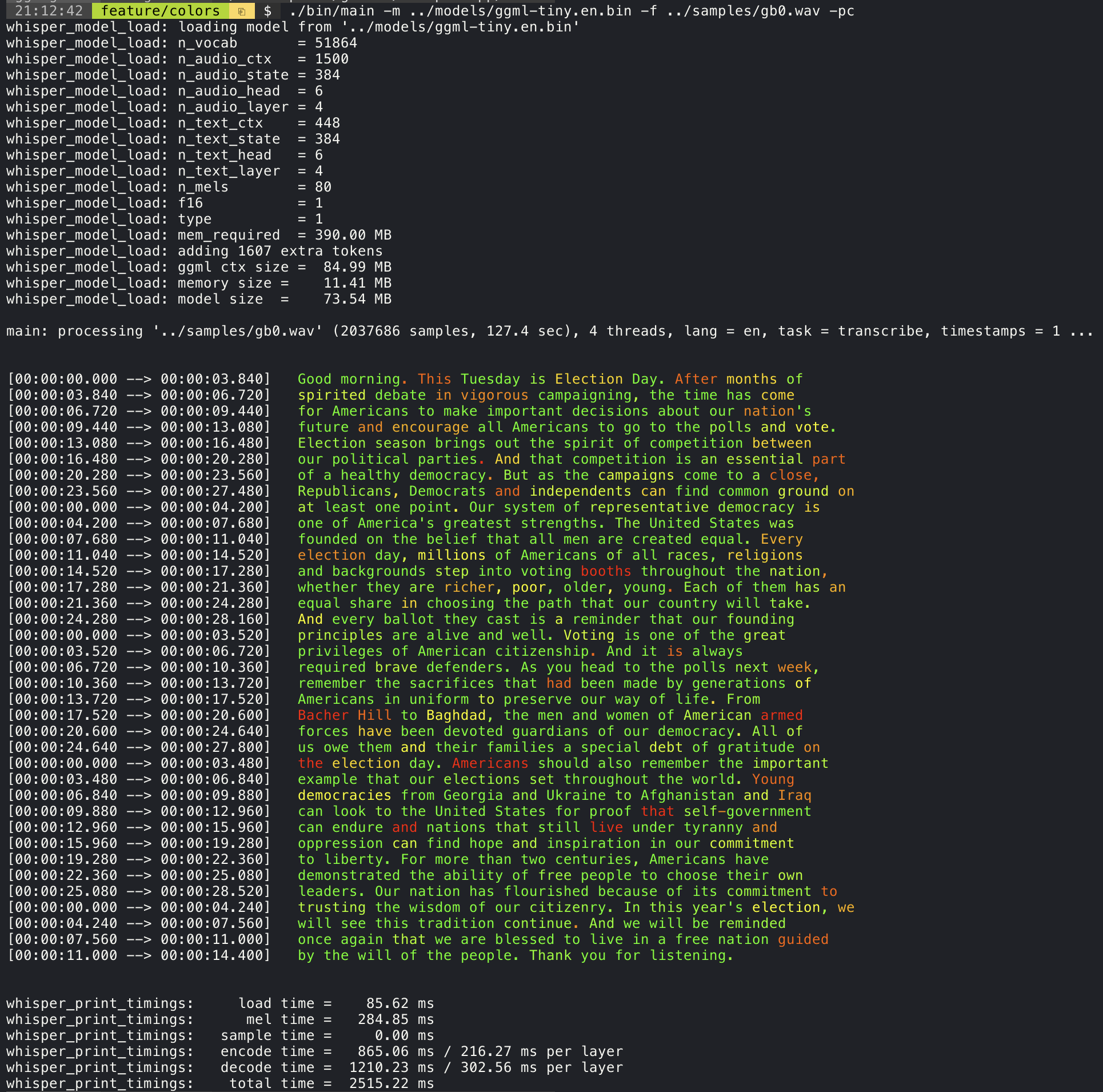
For example, to limit the line length to a maximum of 16 characters, simply add -ml 16:
$ ./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
The --max-len argument can be used to obtain word-level timestamps. Simply use -ml 1:
$ ./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
More information about this approach is available here: #1058
Sample usage:
# download a tinydiarize compatible model
./models/download-ggml-model.sh small.en-tdrz
# run as usual, adding the "-tdrz" command-line argument
./build/bin/whisper-cli -f ./samples/a13.wav -m ./models/ggml-small.en-tdrz.bin -tdrz
...
main: processing './samples/a13.wav' (480000 samples, 30.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, tdrz = 1, timestamps = 1 ...
...
[00:00:00.000 --> 00:00:03.800] Okay Houston, we've had a problem here. [SPEAKER_TURN]
[00:00:03.800 --> 00:00:06.200] This is Houston. Say again please. [SPEAKER_TURN]
[00:00:06.200 --> 00:00:08.260] Uh Houston we've had a problem.
[00:00:08.260 --> 00:00:11.320] We've had a main beam up on a volt. [SPEAKER_TURN]
[00:00:11.320 --> 00:00:13.820] Roger main beam interval. [SPEAKER_TURN]
[00:00:13.820 --> 00:00:15.100] Uh uh [SPEAKER_TURN]
[00:00:15.100 --> 00:00:18.020] So okay stand, by thirteen we're looking at it. [SPEAKER_TURN]
[00:00:18.020 --> 00:00:25.740] Okay uh right now uh Houston the uh voltage is uh is looking good um.
[00:00:27.620 --> 00:00:29.940] And we had a a pretty large bank or so.The whisper-cli example provides support for output of karaoke-style movies, where the
currently pronounced word is highlighted. Use the -wts argument and run the generated bash script.
This requires to have ffmpeg installed.
Here are a few "typical" examples:
./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4jfk.wav.mp4
./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4mm0.wav.mp4
./build/bin/whisper-cli -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4gb0.wav.mp4
Use the scripts/bench-wts.sh script to generate a video in the following format:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4jfk.wav.all.mp4
In order to have an objective comparison of the performance of the inference across different system configurations, use the whisper-bench tool. The tool simply runs the Encoder part of the model and prints how much time it took to execute it. The results are summarized in the following Github issue:
Additionally a script to run whisper.cpp with different models and audio files is provided bench.py.
You can run it with the following command, by default it will run against any standard model in the models folder.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2It is written in python with the intention of being easy to modify and extend for your benchmarking use case.
It outputs a csv file with the results of the benchmarking.
The original models are converted to a custom binary format. This allows to pack everything needed into a single file:
- model parameters
- mel filters
- vocabulary
- weights
You can download the converted models using the models/download-ggml-model.sh script or manually from here:
For more details, see the conversion script models/convert-pt-to-ggml.py or models/README.md.
- Rust: tazz4843/whisper-rs | #310
- JavaScript: bindings/javascript | #309
- React Native (iOS / Android): whisper.rn
- Go: bindings/go | #312
- Java:
- Ruby: bindings/ruby | #507
- Objective-C / Swift: ggerganov/whisper.spm | #313
- .NET: | #422
- Python: | #9
- stlukey/whispercpp.py (Cython)
- AIWintermuteAI/whispercpp (Updated fork of aarnphm/whispercpp)
- aarnphm/whispercpp (Pybind11)
- abdeladim-s/pywhispercpp (Pybind11)
- R: bnosac/audio.whisper
- Unity: macoron/whisper.unity
There are various examples of using the library for different projects in the examples folder. Some of the examples are even ported to run in the browser using WebAssembly. Check them out!
| Example | Web | Description |
|---|---|---|
| whisper-cli | whisper.wasm | Tool for translating and transcribing audio using Whisper |
| whisper-bench | bench.wasm | Benchmark the performance of Whisper on your machine |
| whisper-stream | stream.wasm | Real-time transcription of raw microphone capture |
| whisper-command | command.wasm | Basic voice assistant example for receiving voice commands from the mic |
| whisper-server | HTTP transcription server with OAI-like API | |
| whisper-talk-llama | Talk with a LLaMA bot | |
| whisper.objc | iOS mobile application using whisper.cpp | |
| whisper.swiftui | SwiftUI iOS / macOS application using whisper.cpp | |
| whisper.android | Android mobile application using whisper.cpp | |
| whisper.nvim | Speech-to-text plugin for Neovim | |
| generate-karaoke.sh | Helper script to easily generate a karaoke video of raw audio capture | |
| livestream.sh | Livestream audio transcription | |
| yt-wsp.sh | Download + transcribe and/or translate any VOD (original) | |
| wchess | wchess.wasm | Voice-controlled chess |
If you have any kind of feedback about this project feel free to use the Discussions section and open a new topic.
You can use the Show and tell category
to share your own projects that use whisper.cpp. If you have a question, make sure to check the
Frequently asked questions (#126) discussion.