We present a simple application which can translate Chinese Speech to Nepali Speech offline. For this we are using Machine Learning Approach.
This file records 3 seconds input from your microhone and returns you the nepali translation.
pip install pyaudio pip install speechrecognition pip install sphinx
At first few seconds sample of Chinese speech is taken . For this propose CMU Sphinx Open Source Toolkit For Speech Recognition is used.
python cn_asr.py
After Chinese text is generated from the speech it proceeds to the translation to Nepalese Text. For the translation we train our Ch-Np Dataset
- Bible corpus dataset is used for training
To train the model and predict
python scratch_transformer.py
The transformer model introduces an architecture that is solely based on attention mechanism and does not use any Recurrent Networks but yet produces results superior in quality to Seq2Seq models. It addresses the long term dependency problem of the Seq2Seq model. The transformer architecture is also parallelizable and the training process is considerably faster.

Decoder: The decoder also consists of 6 identical layers with an additional sublayer in each of the 6 layers. The additional sublayer performs multi-head attention over the output of the encoder stack.
Attention Mechanism:
Attention is the mapping of a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The attention mechanism allows the model to understand the context of a text.
- Scaled Dot-Product Attention:

- Multi-Head Attention:

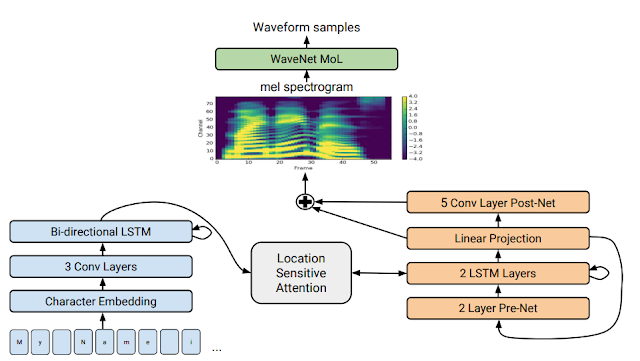
Nepali text generated from transformer model is converted to speech. Tacotron 2 model is used for making TTS system. Tacotron 2, a neural network architecture for speech synthesis directly from text. The system is composed of a recurrent sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms, followed by a modified WaveNet model acting as a vocoder to synthesize timedomain waveforms from those spectrograms. This model achieves a mean opinion score (MOS) of 4.53 comparable to a MOS of 4.58 for professionally recorded speech. To validate our design choices, we present ablation studies of key components of our system and evaluate the impact of using mel spectrograms as the input to WaveNet instead of linguistic, duration, and F0 features. We further demonstrate that using a compact acoustic intermediate representation enables significant simplification of the WaveNet architecture.